Building for Long-Horizon Agents
The most important companies will soon be powered by long-running agents: AIs that work for minutes, hours, or days to complete tasks on behalf of people. Data already works this way. Data pipelines, ETL jobs, nightly batch runs, & scheduled workflows make up the bulk of compute inside any large organization. Agentic AI will follow the same path, but the infrastructure to support it still has to be built.
Today we're announcing Theory Ventures' investment in Sail Research's Series A, alongside our friends at Kleiner Perkins, Redpoint, & Sequoia.
Sail is building the inference platform for long-horizon agents, letting complex agents run and scale as they begin to power our most valuable work.
As AI expands further into the workforce, agents will be multi-turn by default: systems that research, code, & reason across minutes and hours, orchestrating over many models and many steps. Today's inference stack provides the opposite: single-shot, latency-obsessed chat, with a human waiting on the other end. If you were to force a long-horizon agent through that stack, the costs and brittleness show up immediately.
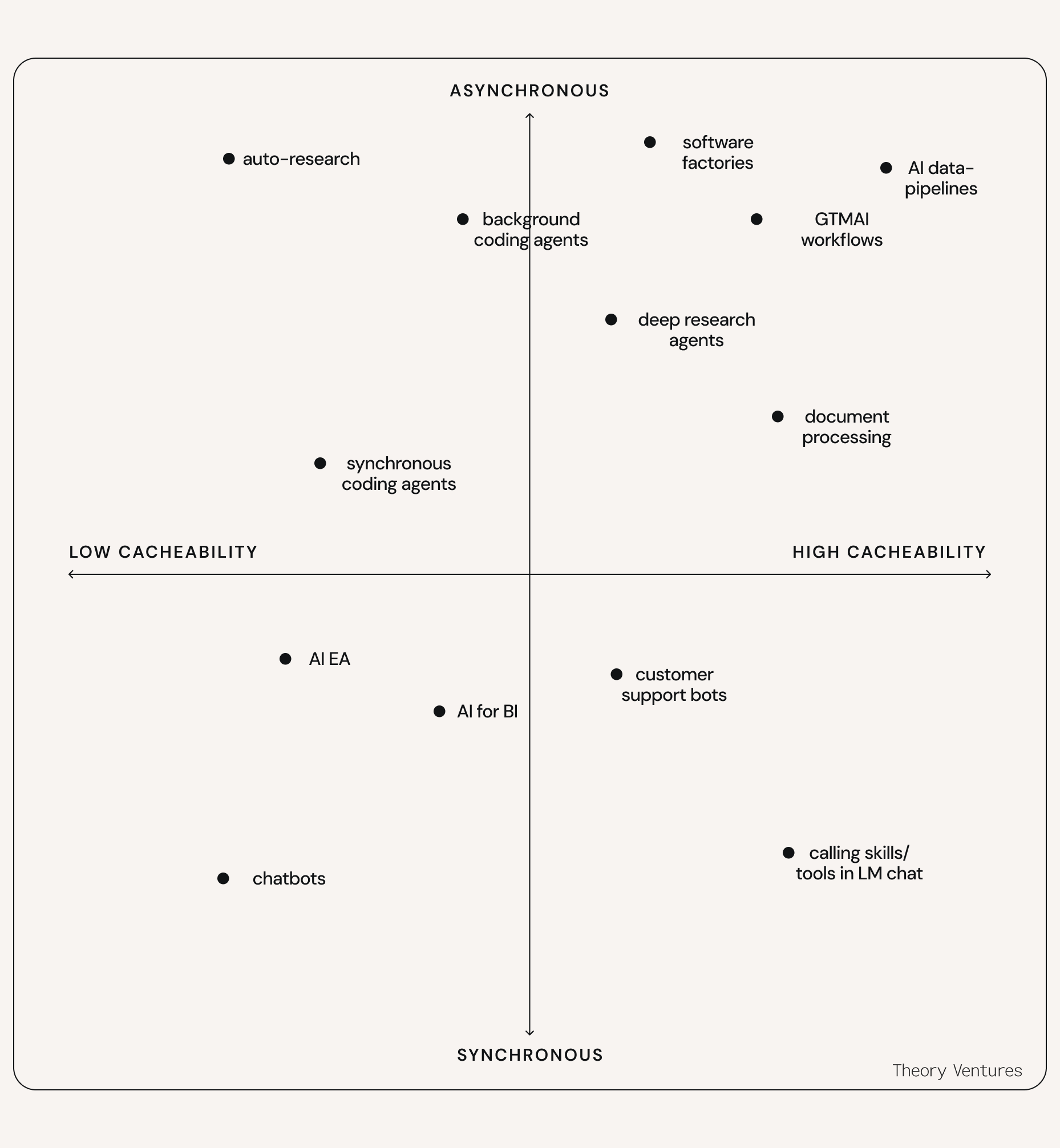
AI workloads can be mapped by how synchronous they are, whether a human is waiting on the other end, and how much repetition they contain (allowing them to take advantage of the cache). On this plane, they fall into two camps. In one corner, fully synchronous and totally unique: work where every second counts and nothing looks the same: chatbots, customer support, BI copilots. At the other, fully asynchronous work that follows a recipe: software factories, AI data-pipelines, overnight document processing. The semi-synchronous middle is work that needs an answer in seconds to minutes, not instantly nor overnight. It sits relatively empty. Not for lack of demand, but because running it on a real-time stack means paying real-time prices, so teams are forced to complete tasks async or never build it at all. If you make that middle section cheap to serve, it fills with deep-research agents, background coding, and agentic GTM workflows. We believe that Sail will enable this middle section to exist.
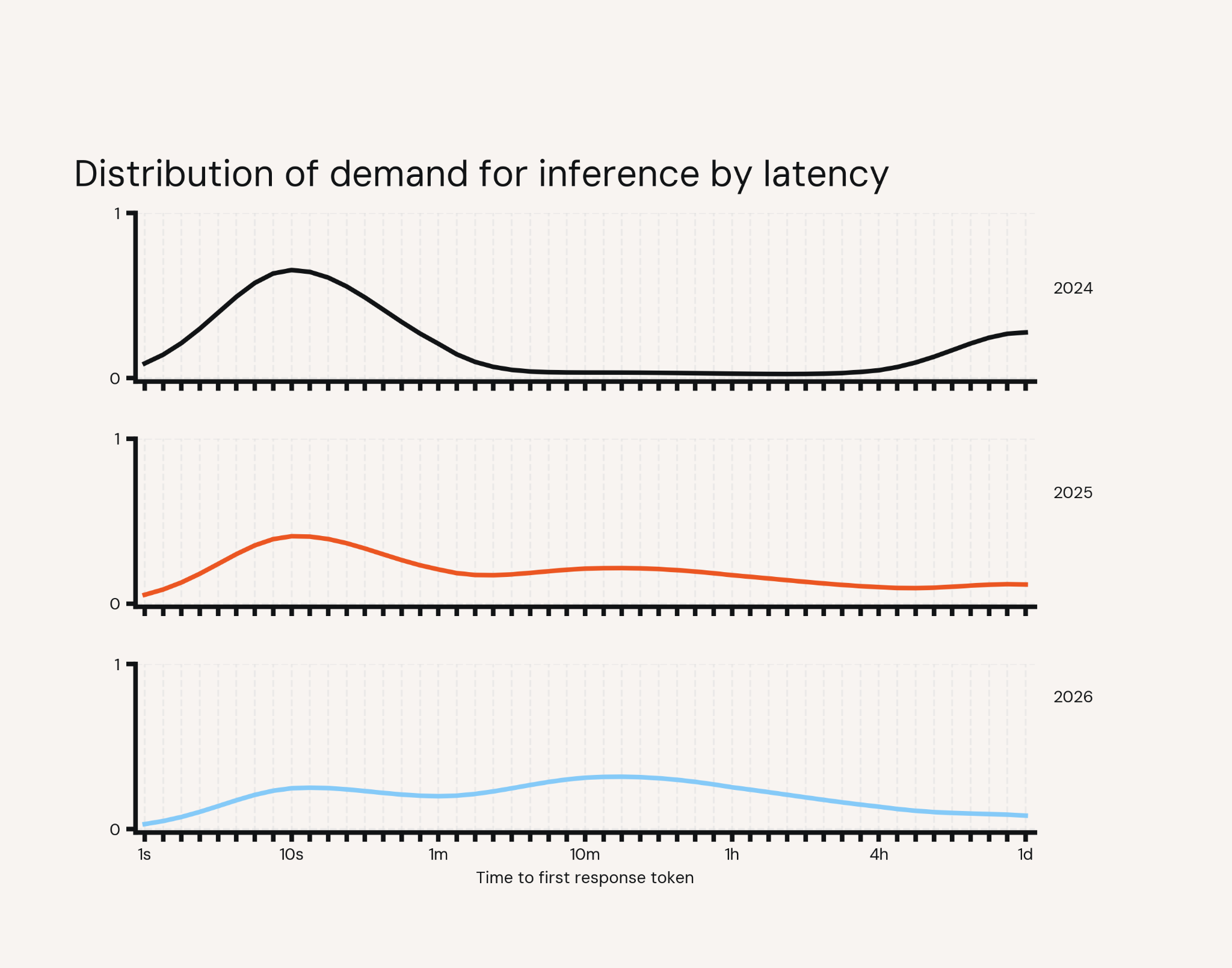
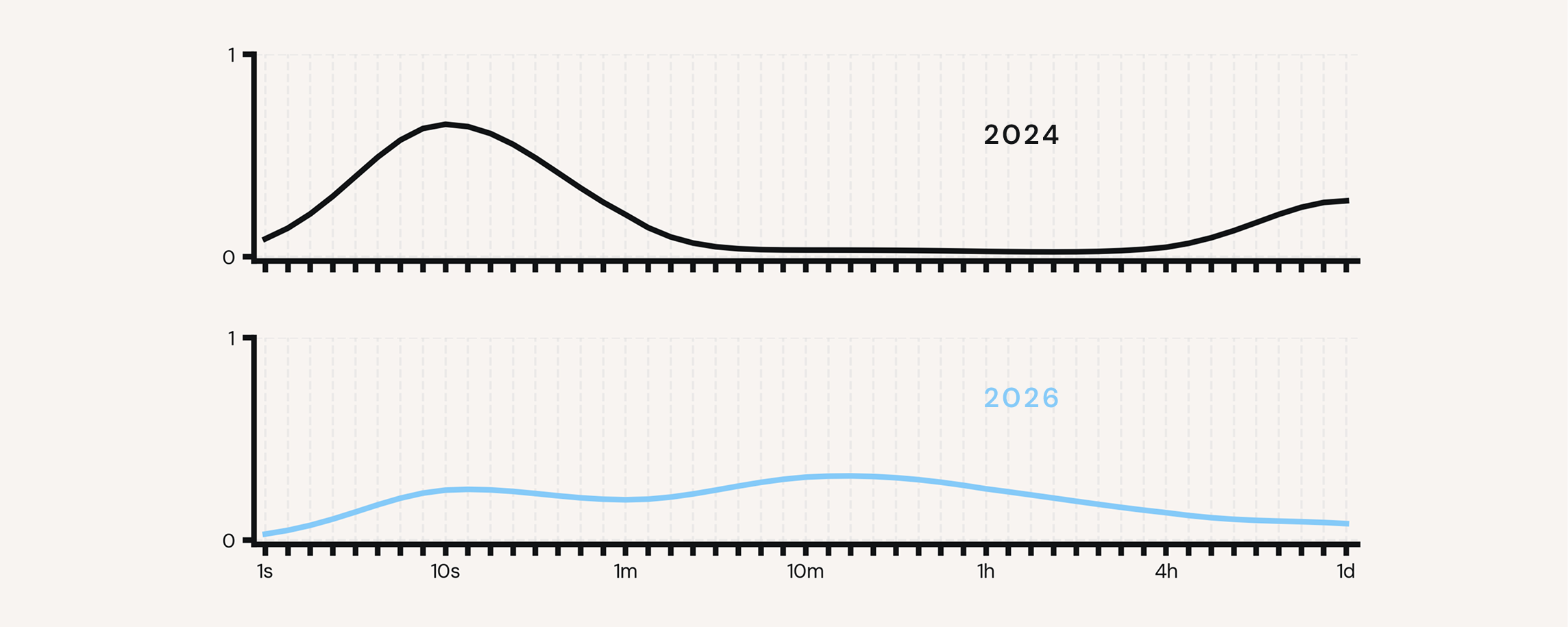
Two years ago, almost all inference demand clustered in the first few seconds — someone typing, a chatbot answering. Each year since, the curve has flattened and spread to the right, as more work moves to agents. That's the semi-sync middle filling in. The market is aggressively starting to demand infrastructure to support this. As agents move into production, token consumption compounds: more turns, more context, more models, for every agent. Token spend is fast becoming one of the largest line items on the CFO's P&L. Companies want to be on the right side of that trade: getting more out of every token, instead of downgrading to weaker models or capping what their agents can do.
And the models are ready too. Open weights like DeepSeek, Qwen, Kimi, & Nemotron are now good enough for the bulk of agentic work and the newest, like GLM, are built for long-horizon agents from the ground up. This open-source race will only accelerate with American labs like Reflection AI spending billions to ship open frontier models of their own. All of this further reduces total inference spend, so the bottleneck isn't the model anymore. It's the infrastructure: how do you get the most out of every dollar of model spend without giving up quality?
Sail's answer is fleet-aware orchestration. Inference becomes a schedulable workload, distributed across models, providers, and hardware to keep utilization high and cost low. The result: up to 10x more tokens per dollar, delivered through drop-in OpenAI- & Anthropic-compatible APIs running the best open models.
Because Sail sits at the orchestration layer, it can see something the layers below can't: when an agent is thinking versus acting. That’s what makes long-horizon agents semi-synchronous, rather than batched or real-time. An agent works in bursts via a flurry of activity, then long, idle stretches waiting on a tool call, a model response, or its own reasoning.
Today's sandboxes are built for the opposite. They compete on shaving milliseconds off cold-start, which does matter when a human is waiting on the other end, but less so for an agent running on its own for hours. This is why Sail built Sailboxes: cloud computers made for that bursty, semi-sync rhythm. A Sailbox stays alive as long as the agent needs, holding state across the entire task, but drops to near-zero cost the moment the agent goes idle and wakes the instant a trigger arrives. You pay only for active time – no start/stop APIs, no paying for idle. That's what makes it economical to run an agent for hours or days and to push far more work through Sail's core inference product along the way.
The platform is already live, running production agent workloads for some of the most important AI companies in the world. Along the way, Sail won BrowseComp-Plus, the deep-research benchmark, and ran a four-agent swarm for 27 hours straight to build Redis in Rust.
Neil Movva & Samir Menon have spent their careers on the hard parts of this problem. Neil chased GPU speed-of-light at NVIDIA, shipped some of the most efficient computer vision algorithms in the world at Apple, and helped build one of the fastest LLM inference stacks at Together AI. Samir comes out of Apple's security engineering team and a deep background in applied cryptography, including prior work running LLMs inside hardware enclaves at Blyss. This is exactly the foundation you want for secure, multi-tenant inference at scale.
We believe agentic AI follows the same arc as every enterprise workload before it, and that async inference will become the largest and most widely used segment of AI compute. As agents grow up from chat assistants into background workers scanning codebases overnight, processing every document, enriching every row of the CRM, the vast majority of tokens become like an ETL job: high-volume, multi-turn, & nobody waiting on the other end.
We're thrilled to partner with Neil, Samir, & the Sail Research team.
The future runs in the background. If you're building agents for it, you can get started here.
